| tags: [ gitlab ci gitlab-ci up-and-running ]
Gitlab CI: Up and running
In this blog post we will implement a “basic” CI flow for a NodeJS project.
Using this skeleton, and iterating on it, you should be able to quickly have a CI for any project on Gitlab.
Steps
We will firstly create a basic CI that: builds, tests and deploy at every push to any branch. We will then add a per-branch cache. And finally we will limit deploys to release branch only.
For this article the deploy stage will only be a curl example.org.
This is only a skeleton example of what a real CI would look like.
Step 1: Draft
The goal here is to have a minimal working CI. We build/test/deploy on each push to any branch.
image: node:10-alpine
variables:
GLOBAL_AWESOME_VAR: hello
stages:
- build
- test
- deploy
before_script:
- npm install
build:
stage: build
script:
- echo 'Inside the job build'
- 'echo "Do you want to see my global awesome var: $GLOBAL_AWESOME_VAR"'
unit:
stage: test
script:
- echo 'Inside the job test'
- npm run unit-test
integration:
stage: test
script:
- echo 'Inside the job test'
- npm run integration-test
deploy:
stage: deploy
before_script:
- echo 'From the overrided before_script'
script:
- curl example.org
How to read this file:
- First we define the base docker
imagethat will be used to run our jobs, as we are working on a Nodejs project we are usingnode:10-alpine(an Alpine linux with Nodejs 10 installed) - We define some environment
variablesthat will be present in each of our job - Then we define our
stages, here our CI will be composed of 3 stages, each stage can have 0 to n jobs - We define a
before_scriptthat will be run before each of our job - We define 4 jobs each in a different stage
How does it translates into a CI:
- Because of the
before_scriptwe will runnpm installbefore anyscriptof each job (except fordeploybecause we locally override it) - First it will run the job
build - Then (simultaneously) run jobs
unitandintegration - Then the
deployjob
As for any CI, if any job fails it will finish executing the jobs in the current failing stage but not the next one.
This will get us this CI:

As you can see our deploy stage fails, the image we are using does not have
curl, we will fix that in the next step.
Step 2: Add some cache
As you saw in the previous step, using the before_script we were always
downloading all the dependencies of our repo before running any job.
In this step we will leverage Gitlab-CI cache to only download the dependencies
once (in the build job) and use it in the next jobs.
image: node:10-alpine
variables:
GLOBAL_AWESOME_VAR: hello
stages:
- build
- test
- deploy
before_script:
- echo 'From global before_script'
build:
stage: build
script:
- echo 'Inside the job build'
- 'echo "Do you want to see my global awesome var: $GLOBAL_AWESOME_VAR"'
- npm install
cache:
key: $CI_COMMIT_REF_SLUG
paths:
- node_modules/
unit:
stage: test
before_script:
- echo 'From the overrided before_script'
script:
- echo 'Inside the job test'
- npm run unit-test
cache:
key: $CI_COMMIT_REF_SLUG
policy: pull
paths:
- node_modules/
integration:
stage: test
before_script:
- echo 'From the overrided before_script'
script:
- echo 'Inside the job test'
- npm run integration-test
cache:
key: $CI_COMMIT_REF_SLUG
policy: pull
paths:
- node_modules/
deploy:
image: rowern/docker-aws
stage: deploy
script:
- curl example.org
As you can see we added some cache directives to most of our jobs.
How does gitlab-ci cache works:
- Before running the job, if the
cachepolicy is empty orpull:- try to download the cache of the provided key (here
$CI_COMMIT_REF_SLUG, the branch name of the running pipeline). If found, it will extract the provided keys (herenode_modules).
- try to download the cache of the provided key (here
- At the end of the job, if the the
cachepolicy is empty orpush:- try to upload the file content of the provided keys (here
node_modules) to the cache with the key$CI_COMMIT_REF_SLUG.
- try to upload the file content of the provided keys (here
In this example our pipeline will have one cache per branch. The key is a variable, it will expand into the name of the branch.
It’s possible to define multiple cache key in the same pipeline (ex: a repository where multiple project reside (iOS + Android))
We also fixed the issue with the deploy stage by specifying the image used
for this specific job (the others will use the globally defined one
node:10-alpine).
Build job (downloading old cache, running the job and pushing the new one):
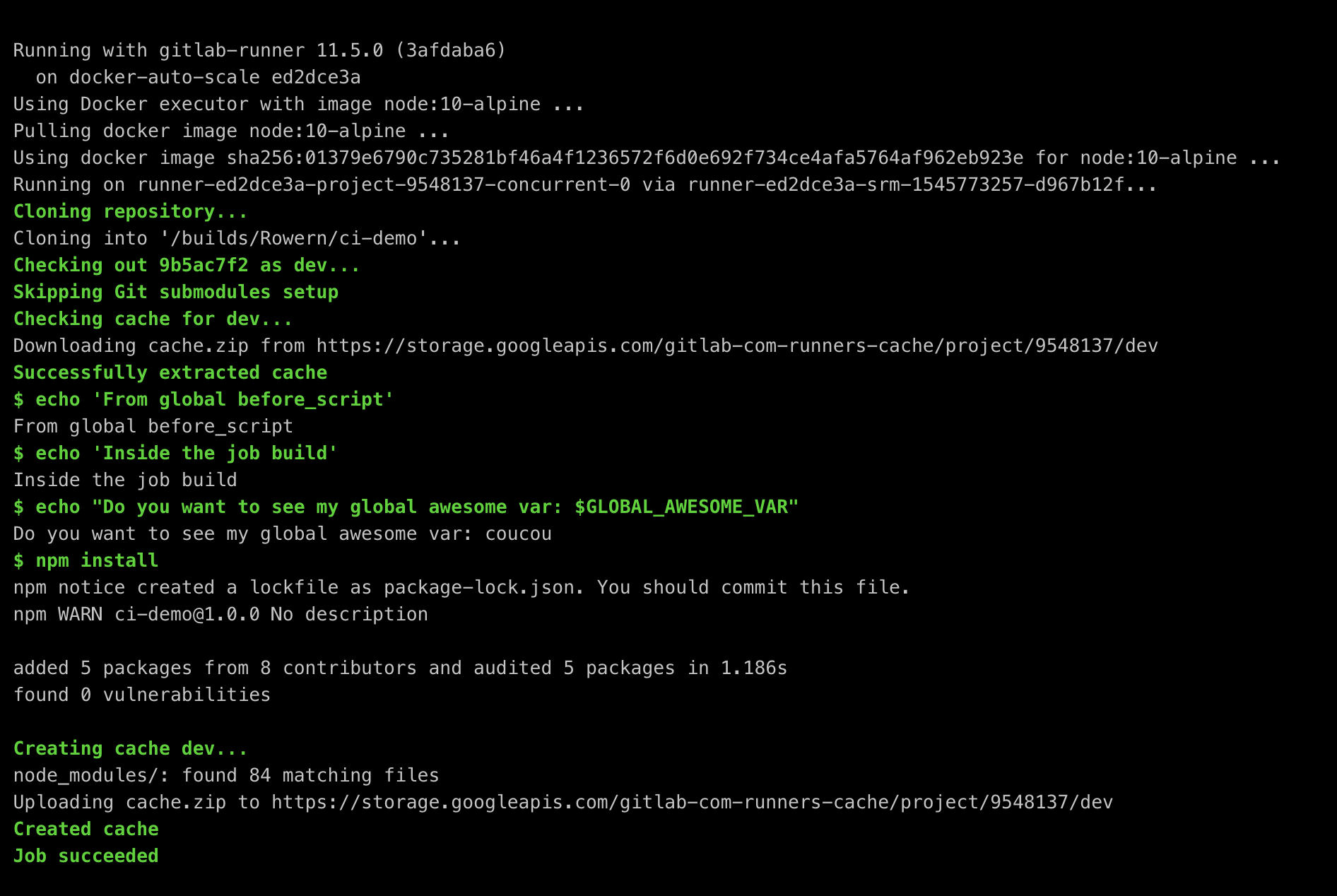 Integration job (downloading the cache but not uploading it because of the policy):
Integration job (downloading the cache but not uploading it because of the policy):
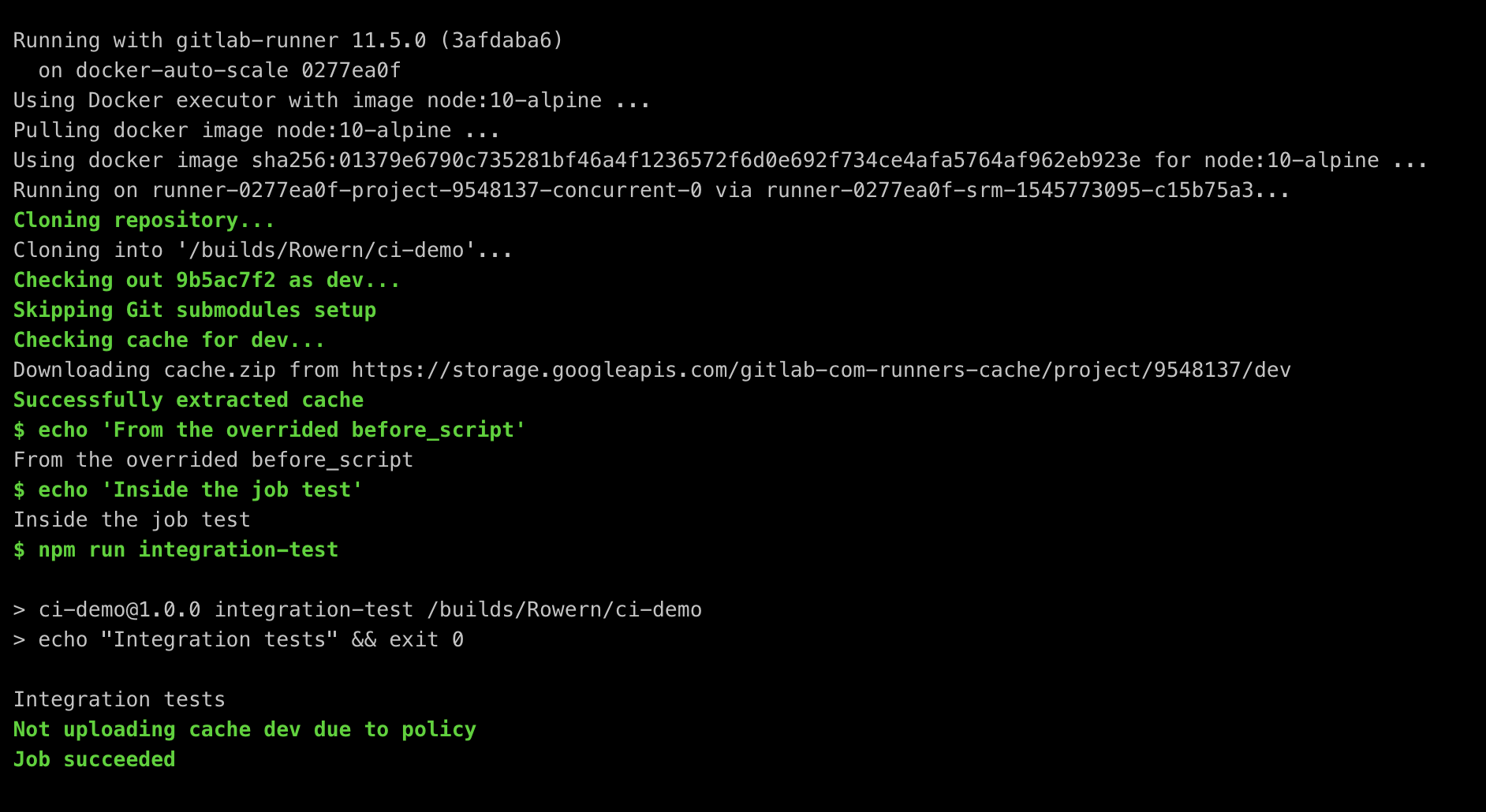
Step 3: Run jobs on specific branches
Here we will limit the integration and the deploy jobs to release branches.
We also do not want to run anything when we push tags.
image: node:10-alpine
stages:
- build
- test
- deploy
variables:
GLOBAL_AWESOME_VAR: coucou
before_script:
- echo 'From global before_script'
build:
stage: build
script:
- echo 'Inside the job build'
- 'echo "Do you want to see my global awesome var: $GLOBAL_AWESOME_VAR"'
- npm install
except:
refs:
- tags
cache:
key: $CI_COMMIT_REF_SLUG
paths:
- node_modules/
unit:
stage: test
before_script:
- echo 'From the overrided before_script'
script:
- echo 'Inside the job test'
- npm run unit-test
except:
refs:
- tags
cache:
key: $CI_COMMIT_REF_SLUG
policy: pull
paths:
- node_modules/
integration:
stage: test
before_script:
- echo 'From the overrided before_script'
script:
- echo 'Inside the job test'
- npm run integration-test
except:
refs:
- tags
only:
refs:
- /.*release.*/
cache:
key: $CI_COMMIT_REF_SLUG
policy: pull
paths:
- node_modules/
deploy:
image: rowern/docker-aws
stage: deploy
script:
- curl example.org
except:
refs:
- tags
only:
refs:
- /.*release.*/
To achieve this we used the only and except directives:
except:refswith the valuetags=> Do not run any jobs when tags are pushed to this repositoryonly:refswith the value/.*release.*/=> Only run theintegrationand thedeployjob when a commit is pushed to a branch matching the regexp/.*release.*/
CI on a non-release branch:

CI on a release branch:
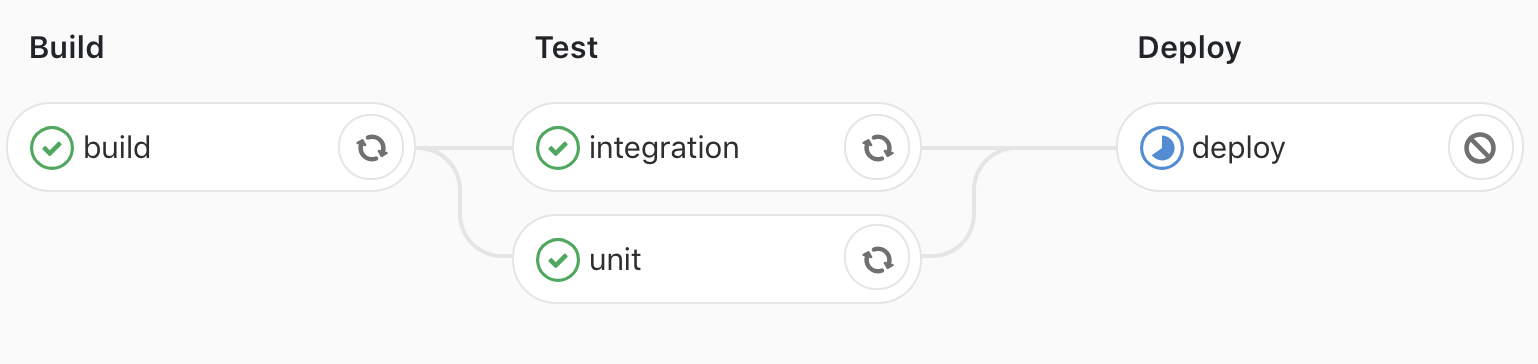
Step 5: Only running the deploy job manually
In the previous step we made sure that only a release branch would run
integration and deploy jobs.
As the deploy job is critical, we will make it into a manual job (i.e. the job
will need some human interaction to be runned).
image: node:10-alpine
stages:
- build
- test
- deploy
variables:
GLOBAL_AWESOME_VAR: coucou
before_script:
- echo 'From global before_script'
build:
stage: build
script:
- echo 'Inside the job build'
- 'echo "Do you want to see my global awesome var: $GLOBAL_AWESOME_VAR"'
- npm install
except:
refs:
- tags
cache:
key: $CI_COMMIT_REF_SLUG
paths:
- node_modules/
unit:
stage: test
before_script:
- echo 'From the overrided before_script'
script:
- echo 'Inside the job test'
- npm run unit-test
except:
refs:
- tags
cache:
key: $CI_COMMIT_REF_SLUG
policy: pull
paths:
- node_modules/
integration:
stage: test
before_script:
- echo 'From the overrided before_script'
script:
- echo 'Inside the job test'
- npm run integration-test
except:
refs:
- tags
only:
refs:
- /.*release.*/
cache:
key: $CI_COMMIT_REF_SLUG
policy: pull
paths:
- node_modules/
deploy:
image: rowern/docker-aws
stage: deploy
script:
- curl example.org
except:
refs:
- tags
only:
refs:
- /.*release.*/
when: manual
allow_failures: false
We added the when directive to the deploy job.
We also restricted this job so that it will not be possible to run it if any
previous job failed (allow_failures). We need this because a manual job
without this directive will be authorized to run even if a previous job failed.
The deploy job after this step:
Conclusion
Using this example and adapting it to your own codebase you should be able to add a CI to your project to improve code quality (making a Merge requests un-mergeable until a pipeline passes), reproductability (you have only the Gitlab CI to check to determine what/how your project was build/deployed) and productivity (your devs won’t need to worry about manually running tests or deploying).